

| Tree Fuzzification Factor | Excluding fields from the target table | |
 The Fields Usage tab of a MinedTree object is designed to summarize the 'Data Source' and select the data fields for mining. The Window displays a list of the fields in the data source table.
The Fields Usage tab of a MinedTree object is designed to summarize the 'Data Source' and select the data fields for mining. The Window displays a list of the fields in the data source table.
The Fields Usage tab offers the following facilities:
·Scanning the data source to build up a summary statistical picture of the data fields within it. It will report on numeric and date/time fields by showing the minimum value, maximum value, standard deviation and non-numeric values. For discrete fields, it will report on the frequency of all discrete values. Such reporting, will give the developer a first level understanding of what the data source table contains. See Understanding the data.
·You can set which data fields to consider as attribute fields, which to exclude, and which to consider as the dependent outcome field.
·Grouping of discrete values or numeric ranges can be defined manually for any data field.
· Automatic grouping of values of attribute fields in accordance with their effect on the current outcome field.
Automatic grouping of values of attribute fields in accordance with their effect on the current outcome field.
· Automatic Ranking of the attributes in accordance with their effect on the current outcome. This will show the order in the Rank column.
Automatic Ranking of the attributes in accordance with their effect on the current outcome. This will show the order in the Rank column.
When you select a field from the table (Age is selected in the example below) you can view a statistics summary or graph, by pressing the appropriate tab in the right-hand window pane.
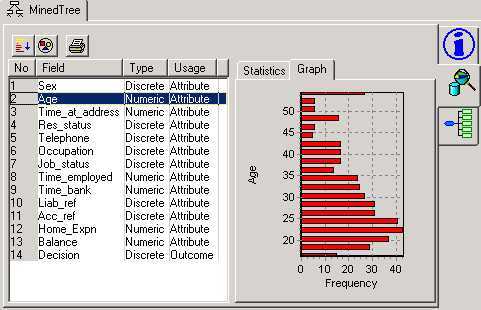
Note that the graphs always reflect the distribution frequencies of the whole data - whereas the report graphs (which you can set up using New Tree Report) can change as you move around the tree to show the distribution frequencies at the current selected node in the tree. This gives you a very visual way to compare the differences between the root of the tree and lower nodes.
Field names
By default, the field names will be obtained from the first 40 characters of the name that is used within the data source table. To change the name simply select the field then from the Statistics tab rename the Field and click on the Apply Name Change button  . The new name applies within the Mined Tree object but the field name in the data remains unchanged.
. The new name applies within the Mined Tree object but the field name in the data remains unchanged.
Field Type
The field type will be taken from the data source as either Discrete (i.e. text/string), Numeric, or Date/time.
Usage
Fields have three usage settings.
Attribute: Using this setting designates the field as an attribute when building the tree. This is the default setting for all fields.
Outcome: The sets the field to be used as the dependant outcome. There can only be one field set to the outcome field at one time. To be able to mine the data and generate a tree you must set one of the fields as the outcome and you must also have at least two fields set as attributes - otherwise the mining algorithms have no foundation on which to start.
Setting another field to the outcome would automatically reset any existing outcome back to attribute usage, and would also delete (i.e. clear) the current tree on the Tree window.
Excluded: The field is to be totally excluded from the analysis when tree building. That is, it will be ignored until such time as you change it to an attribute.
 You can use CTRL+click to select several fields on the table view to perform the same action on them, e.g. to change usage. You can also use drag & drop to take fields from the table view and create new branches on your trees. You can resize all the columns and panes of the Table view window. Just hold and drag on any of the lines/separators. To change column widths you move the lines at the column headings.
You can use CTRL+click to select several fields on the table view to perform the same action on them, e.g. to change usage. You can also use drag & drop to take fields from the table view and create new branches on your trees. You can resize all the columns and panes of the Table view window. Just hold and drag on any of the lines/separators. To change column widths you move the lines at the column headings.